高效 Debug
排查 Panic 原因
虽然 Panic 问题不全是因为并发导致的,但是非并发导致的 Panic 往往都比较容易通过代码 Review 排查,所以这里只讨论并发引起的 Panic 问题。
假设我们现在有如下代码,Handle 函数在 ctx 超时结束时,会直接返回 resp。但该函数存在一个潜在的并发问题是,当 Process 函数已经获得 Response 变量时,依然有可能在之后被修改,从而产生了并发问题。
func Handle(ctx context.Context) *Response {
done := make(chan struct{})
resp := &Response{Data: []byte("12345")} // default value
go func() {
runtime.Gosched() // mock network call¬s
resp.Data = nil
close(done)
}()
select {
case <-ctx.Done(): // canceled
case <-done:
}
return resp
}
func Process(ctx context.Context) {
resp := Handle(ctx)
size := len(resp.Data)
if size > 0 {
runtime.Gosched()
fmt.Println(resp.Data[:size])
}
}
通过 Stack 排查
上述代码在遇到并发冲突时的 Stack 如下:
panic: runtime error: slice bounds out of range [:5] with capacity 0 [recovered]
panic: runtime error: slice bounds out of range [:5] with capacity 0
goroutine 6 [running]:
testing.tRunner.func1.2(0x113c6c0, 0xc00008c000)
/usr/local/go/src/testing/testing.go:1144 +0x332
testing.tRunner.func1(0xc000001380)
/usr/local/go/src/testing/testing.go:1147 +0x4b6
panic(0x113c6c0, 0xc00008c000)
/usr/local/go/src/runtime/panic.go:965 +0x1b9
chore/example.Process(0x1178d68, 0xc000022480)
/Users/bytedance/Code/go/chore/example/panic_test.go:36 +0xf8
chore/example.TestPanic(0xc000001380)
/Users/bytedance/Code/go/chore/example/panic_test.go:44 +0x85
testing.tRunner(0xc000001380, 0x11557f8)
/usr/local/go/src/testing/testing.go:1194 +0xef
created by testing.(*T).Run
/usr/local/go/src/testing/testing.go:1239 +0x2b3
- 找到 panic 原因
首先我们需要知道导致我们 Panic 的真正原因是什么,可以在完整的 panic stack 最上面一行找到。
如这里就是 panic: runtime error: slice bounds out of range [:5] with capacity 0 [recovered]。
-
找到原始 panic 位置
其次,我们还需要找到真正触发 Panic 的代码在哪里。任何 panic stack 都会包含至少一条
runtime/panic.go的日志,该日志的下一条便是真正触发 Panic 的代码行。如这里是example/panic_test.go:36。但有些时候,用户的 panic 会被上层 recover 函数所包裹,例如:
func WrapPanic(ctx context.Context) { defer func() { err := recover() if err != nil { panic(err) } }() Process(ctx) }此时的 panic 会变成如下:
panic: runtime error: slice bounds out of range [:5] with capacity 0 [recovered] panic: runtime error: slice bounds out of range [:5] with capacity 0 [recovered] panic: runtime error: slice bounds out of range [:5] with capacity 0 goroutine 18 [running]: testing.tRunner.func1.2(0x113c7c0, 0xc00011c000) /usr/local/go/src/testing/testing.go:1144 +0x332 testing.tRunner.func1(0xc000082600) /usr/local/go/src/testing/testing.go:1147 +0x4b6 panic(0x113c7c0, 0xc00011c000) /usr/local/go/src/runtime/panic.go:965 +0x1b9 chore/example.WrapPanic.func1() /Users/bytedance/Code/go/chore/example/panic_test.go:47 +0x55 panic(0x113c7c0, 0xc00011c000) /usr/local/go/src/runtime/panic.go:965 +0x1b9 chore/example.Process(0x1178e68, 0xc000022480) /Users/bytedance/Code/go/chore/example/panic_test.go:38 +0xf8 chore/example.WrapPanic(0x1178e68, 0xc000022480) /Users/bytedance/Code/go/chore/example/panic_test.go:50 +0x57 chore/example.TestPanic(0xc000082600) /Users/bytedance/Code/go/chore/example/panic_test.go:57 +0x85 testing.tRunner(0xc000082600, 0x1155900) /usr/local/go/src/testing/testing.go:1194 +0xef created by testing.(*T).Run /usr/local/go/src/testing/testing.go:1239 +0x2b3panic stack 的顺序是越往下,越是在函数调用链最外层。我们需要找到最先“调用” panic() 的地方,所以需要找最下面的 runtime/panic.go 段,其下面一行便是真正触发 panic 的代码行位置。
通过 Race 溯源
依然以上面的示例代码举例,在代码量很少的情况下,我们能够非常清楚的看到是哪个异步逻辑修改了变量。但在业务代码量非常庞大的情况下,尤其是涉及到第三方库的情况下,我们通过肉眼已经很难判断,此时需要借助工具来帮我们找出罪魁祸首。
单测排查
对于示例中这种修改逻辑都在同一个函数内的情况,我们可以简单写一个单元测试便可以发现问题:
func TestPanic(t *testing.T) {
ctx, cancelFn := context.WithTimeout(context.Background(), time.Millisecond)
cancelFn() // ctx is done
Process(ctx)
}
然后我们通过 go test -race ./panic_test.go 在开启 race 检测下运行测试函数。Go 会输出日志告诉我们哪些 Goroutine 在并发读写哪些变量,并且会告诉我们这些 Goroutine 的创建位置:
WARNING: DATA RACE
Write at 0x00c000124030 by goroutine 8:
command-line-arguments.Handle.func1()
/Users/bytedance/Code/go/chore/example/panic_test.go:21 +0x44
Previous read at 0x00c000124030 by goroutine 7:
command-line-arguments.Process()
/Users/bytedance/Code/go/chore/example/panic_test.go:35 +0x5b
command-line-arguments.WrapPanic()
/Users/bytedance/Code/go/chore/example/panic_test.go:50 +0x6c
command-line-arguments.TestPanic()
/Users/bytedance/Code/go/chore/example/panic_test.go:56 +0x9a
testing.tRunner()
/usr/local/go/src/testing/testing.go:1194 +0x202
Goroutine 8 (running) created at:
command-line-arguments.Handle()
/Users/bytedance/Code/go/chore/example/panic_test.go:19 +0x116
command-line-arguments.Process()
/Users/bytedance/Code/go/chore/example/panic_test.go:34 +0x46
command-line-arguments.WrapPanic()
/Users/bytedance/Code/go/chore/example/panic_test.go:50 +0x6c
command-line-arguments.TestPanic()
/Users/bytedance/Code/go/chore/example/panic_test.go:56 +0x9a
testing.tRunner()
/usr/local/go/src/testing/testing.go:1194 +0x202
Goroutine 7 (finished) created at:
testing.(*T).Run()
/usr/local/go/src/testing/testing.go:1239 +0x5d7
testing.runTests.func1()
/usr/local/go/src/testing/testing.go:1512 +0xa6
testing.tRunner()
/usr/local/go/src/testing/testing.go:1194 +0x202
testing.runTests()
/usr/local/go/src/testing/testing.go:1510 +0x612
testing.(*M).Run()
/usr/local/go/src/testing/testing.go:1418 +0x3b3
main.main()
_testmain.go:43 +0x236
通过上述 race 报告,我们可以看出以下信息:
- goroutine 8 在 panic_test.go:21 行出现了一次有 race 的写入
- goroutine 7 在 panic_test.go:35 行出现了一次有 race 的读取
- goroutine 7 已经结束,但是 goroutine 8 依然还在运行
根据以上信息,基本上我们已经能够清楚知道问题所在了。
线上排查
有些时候我们并不容易对一些业务逻辑写单测,尤其是涉及到多个上下游服务共同配合才能触发的逻辑。此时就需要依赖于线上排查来验证问题所在。
假如我们有下列代码:
type Request struct {
Id int
}
type Response struct {
Data []byte
}
//go:noinline
func RPCCall(req *Request) *Response {
resp := &Response{Data: []byte("hello")}
if req.Id%100 == 0 { // Logic Bug
go func() {
resp.Data = []byte("world")
}()
}
return resp
}
func main() {
for id := 0; ; id++ {
resp := RPCCall(&Request{Id: id})
if string(resp.Data) != "hello" {
log.Println("abnormal response!")
return
}
}
}
RPCCall 函数用来模拟一个仅会对于特定线上请求参数时,才会出现逻辑 Bug 的 Race 问题。然后我们使用 go build -race 来编译这个程序。
需要注意的是,这种编译方法会大幅降低程序性能, 我们如果能够有流量重放的环境,可以单独针对该实例去重放线上流量以此来复现问题。如果不能流量重放,也只能在个别实例中开启,并做好因为性能降低可能引发超时的准备。
排查 Crash 问题
在 Go 中,进程的非预期退出一般有以下两种原因引起:
- unrecovered panic: 任何一个 Goroutine 中,出现了一个没有被 recover 的 panic 错误
- unexpected exception: Go Runtime 遇到了一个无法恢复的致命错误,常见的比如并发写 Map 冲突(concurrent map writes),访问非法地址(unexpected fault address)等。
Go 默认会对所有异常退出都打印对应的 Stack,对于简单的项目,使用前面排查 Panic 问题时的 Stack 定位方法依然可以直观地看出问题所在。但对于复杂的项目,即便我们能够知道导致退出的位置在哪里,但依然无法判断为什么代码会走到该位置。这时,我们便需要引入能够对整个系统当时状态进行细致分析的工具了。
在 C/C++ 中,一般使用 GDB 进行这类调试,而在 Go 中,我们可以使用专为 Go 运行时特性和数据结构优化的 Delve 工具。
获取 Coredump 文件
被动获取
Delve 工具需要我们传入进程退出时,保存的 coredump 文件。我们需要使用:
# 不限制 coredump 的文件大小
ulimit -c unlimited
# 查看 coredump 文件目录
# 对于由公司统一控制的机器来说,一般这个目录会被指定到 /opt/tiger/cores 。
cat /proc/sys/kernel/core_pattern
# 指示 Go Runtime 处理 coredump
GOTRACEBACK=crash ./{bin_exec}
需要注意的是,Go 对于那些被 recover 的 panic 并不会异常退出,也不会产生 coredump 文件。
主动获取
此外,也并不一定只有程序退出时才能产生 coredump ,如果我们判断某个程序已经进入到异常状态(例如卡死),但是又没有异常退出,此时我们可以通过主动发送 core 信号,让其产生 coredump 以保存现场:
# 强制生成 coredump
apt install gdb
gcore -o server.coredump {pid} # gcore 会暂时让程序停止响应,但并不会杀死程序
通过 Delve 分析
我们通过下面一个会偶发 Crash 的示例代码来展示如何使用 Delve 深入分析问题:
package main
import (
"fmt"
"log"
"sync"
)
var _ error = (*MyError)(nil)
var store sync.Map
func init() {
for id := 0; id < 1000; id++ {
item := &Item{Name: fmt.Sprintf("Item-%d", id)}
store.Store(id, item)
}
}
type MyError struct {
Reason string
}
func (e MyError) Error() string {
return fmt.Sprintf("MyError: %s", e.Reason)
}
func Buy(id int) (*Item, error) {
var err *MyError
val, ok := store.LoadAndDelete(id)
if !ok {
return nil, err
}
item := val.(*Item)
return item, err
}
func Handler(id int) {
item, err := Buy(id)
if item == nil && err != nil {
if merr, ok := err.(*MyError); ok {
log.Printf("Buy[%d] get error: %v", id, merr.Error())
}
return
}
log.Printf("Buy item success: %v", item)
}
func main() {
var wg sync.WaitGroup
for id := 0; id < 1000; id++ {
wg.Add(1)
go func() {
defer wg.Done()
log.Printf("Handling: %d", id)
Handler(id)
}()
}
wg.Wait()
}
type Item struct {
Name string
}
该程序首先在 init 函数中,为 store 变量创建了 1000 个商品 Item,然后在 main 函数中使用 1000 个 Groutine 并发调用 Buy 函数从 store 获取商品。由于购买过程中有可能出现各种异常情况,所以我们封装了 MyError 用来表达购买失败的原因。
该程序运行时,会出现以下 panic 错误并退出:
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x491101]
goroutine 48 [running]:
panic({0x49c4e0, 0x53e0b0})
/usr/local/go/src/runtime/panic.go:941 +0x397 fp=0xc00004ad50 sp=0xc00004ac90 pc=0x437337
runtime.panicmem(...)
/usr/local/go/src/runtime/panic.go:220
runtime.sigpanic()
/usr/local/go/src/runtime/signal_unix.go:826 +0x31d fp=0xc00004ada0 sp=0xc00004ad50 pc=0x44be1d
main.Handler(0x39)
/home/wangzhuowei/code/chore/main.go:41 +0x121 fp=0xc00004aef8 sp=0xc00004ada0 pc=0x491101
main.main.func1()
/home/wangzhuowei/code/chore/main.go:55 +0x159 fp=0xc00004afe0 sp=0xc00004aef8 pc=0x491619
runtime.goexit()
/usr/local/go/src/runtime/asm_amd64.s:1571 +0x1 fp=0xc00004afe8 sp=0xc00004afe0 pc=0x4635e1
created by main.main
/home/wangzhuowei/code/chore/main.go:52 +0xf1
如果你对 Go 的一些常见的编码的坑有一定了解,可能通过阅读这里的代码就能够发现其中蕴藏的几个 Bug,但假设这里的函数都是一些嵌套了几十层复杂代码,甚至牵涉到第三方 SDK 的处理,那么就已经很难通过人肉阅读代码来排查了。
定位直接原因
通过前面讲的方法,我们首先在本机目录中找到 coredump 文件,然后运行:
dlv core {elf_exec} {coredump_file}
进入 coredump 文件后,我们先输入 stack 查看发生 crash 时,程序的 stack 停留在哪里:
(dlv) stack
0 0x0000000000464f01 in runtime.raise
at /usr/local/go/src/runtime/sys_linux_amd64.s:170
1 0x000000000044bf45 in runtime.dieFromSignal
at /usr/local/go/src/runtime/signal_unix.go:860
2 0x000000000044c516 in runtime.sigfwdgo
at /usr/local/go/src/runtime/signal_unix.go:1074
3 0x000000000044ac2a in runtime.sigtrampgo
at /usr/local/go/src/runtime/signal_unix.go:430
4 0x0000000000465cce in runtime.sigtrampgo
at <autogenerated>:1
5 0x00000000004651dd in runtime.sigtramp
at /usr/local/go/src/runtime/sys_linux_amd64.s:363
6 0x00000000004652e0 in runtime.sigreturn
at /usr/local/go/src/runtime/sys_linux_amd64.s:468
7 0x0000000000437b69 in runtime.crash
at /usr/local/go/src/runtime/signal_unix.go:952
8 0x0000000000437b69 in runtime.fatalpanic
at /usr/local/go/src/runtime/panic.go:1092
9 0x0000000000437337 in runtime.gopanic
at /usr/local/go/src/runtime/panic.go:941
10 0x000000000044be1d in runtime.panicmem
at /usr/local/go/src/runtime/panic.go:220
11 0x000000000044be1d in runtime.sigpanic
at /usr/local/go/src/runtime/signal_unix.go:826
12 0x0000000000491101 in main.Handler
at /home/wangzhuowei/code/chore/main.go:41
13 0x0000000000491619 in main.main.func1
at /home/wangzhuowei/code/chore/main.go:55
14 0x00000000004635e1 in runtime.goexit
at /usr/local/go/src/runtime/asm_amd64.s:1571
最左边的数字表示了 stack 中每一个 frame 的层级序号,我们可以使用 frame N 命令进入具体的 frame 中,查看更多信息:
(dlv) frame 12
> runtime.raise() /usr/local/go/src/runtime/sys_linux_amd64.s:170 (PC: 0x464f01)
Frame 12: /home/wangzhuowei/code/chore/main.go:41 (PC: 491101)
36:
37: func Handler(id int) {
38: item, err := Buy(id)
39: if item == nil && err != nil {
40: if merr, ok := err.(*MyError); ok {
=> 41: log.Printf("Buy[%d] get error: %v", id, merr.Error())
42: }
43: return
44: }
45: log.Printf("Buy item success: %v", item)
目前为止的所有信息量,只能让我们知道导致 panic 的直接原因是什么,那就是 merr 不知为何在这里成了 nil 。其实这些信息我们单纯分析 crash 时候的 panic 日志都能获得,但它们远不足以让我们弄清楚事故现场究竟发生了什么,所以我们还需要后续步骤进一步分析找到造成问题的根本原因。
溯源根本原因
从第 41 行代码中我们可以看到,为了拿到真实的 MyError 对象,我们已经做了很多安全保护,先检查了是否为 nil,再检查了是否可以进行类型转换,但依然还是报了 invalid memory address or nil pointer dereference 的错误。所以,我们首先就需要看下 merr 和 err 变量到底在这里是一个什么:
(dlv) print merr
*main.MyError nil
(dlv) print err
error(*main.MyError) nil
可以看到这里 merr 的类型是指针,值为 nil。而 err 的类型是 interface ,它的显示规则为 <interface name>(<concrete type>)<value> ,所以我们得知它是一个类型为 *MyError 值为 nil 的对象。
通过阅读 Go 的源码和文档,我们可以知道在 Go 中,一个有具体类型但是值为 nil 的 interface 对象,并不是等于 nil 的。
接下来的问题是,在什么情况下,会导致 err 有类型,但是值为 nil 呢?我们可以在代码中搜索所有可能声明 var err *MyError 的地方,找到如下位置:
func Buy(id int) (*Item, error) {
var err *MyError
val, ok := store.LoadAndDelete(id)
if !ok {
return nil, err
}
item := val.(*Item)
return item, err
}
这里的 Buy 函数可以很直观的发现,当在 store 中查找不到 id 对象时,就会返回 item 为 nil ,同时 err 值为 nil 类型不为 nil 的对象。
但如果阅读代码最开始的 init 函数,我们实现已经创建了 ID 为 [0, 1000) 范围的所有 Item,且 main 函数也是从 [0,1000) 去调用的 Buy 函数,那么为什么会查不到值呢?于是,我们可以进一步往调用链的深处查找所有相关变量:
(dlv) frame 13
Frame 13: /home/wangzhuowei/code/chore/main.go:55 (PC: 491619)
50: for id := 0; id < 1000; id++ {
51: wg.Add(1)
52: go func() {
53: defer wg.Done()
54: log.Printf("Handling: %d", id)
=> 55: Handler(id)
56: }()
57: }
(dlv) print id
58
(dlv) frame 12
Frame 12: /home/wangzhuowei/code/chore/main.go:41 (PC: 491101)
37: func Handler(id int) {
38: item, err := Buy(id)
39: if item == nil && err != nil {
40: if merr, ok := err.(*MyError); ok {
=> 41: log.Printf("Buy[%d] get error: %v", id, merr.Error())
42: }
(dlv) print id
57
由于这里的 Handler 函数与上层调用函数唯一的联系只有参数 id ,所以我们只需要打印它的值即可。可以看到,在外层 frame 13 中,id 的值为 58,而内层 frame 12 中,它的值为 57,所以我们可以知道,在开始 Handler 调用的时候,id 值为 57 ,而发生 panic 的时候,id 值已经被修改为 58 了。而这是不符合我们预期的,因为这证明了在调用 Handler 函数前,很可能 id 也被修改了,从而使得内层 Buy 函数出现访问到了已经被访问并删除的对象。进而出现上面最终的错误。
当找到这个线索后,我们再根据线索去找会修改 id 值的代码段,便可以清晰地找到真正的问题所在了。即,在 50 行修改了此时正被其他 Goroutine 对象持有的 id 对象。
func main() {
var wg sync.WaitGroup
for id := 0; id < 1000; id++ {
wg.Add(1)
go func() {
defer wg.Done()
log.Printf("Handling: %d", id)
Handler(id)
}()
}
wg.Wait()
}
排查内存泄漏问题
在 Go 中,排查内存泄露类型问题只要有两大难点:
- Go 是自带垃圾回收的语言,不需要用户手动管理对象的生命周期,这也变相导致了,代码中任何一段如果可能会长期持有某个变量,或是部分持有(例如切片)某个地址空间,都可能会导致内存泄露。
- Go pprof heap 只能看到由哪个函数创建了内存,并不能看到谁依然在持有内存引用。目前只能靠阅读代码完成。
假设我们有如下代码,将用户的 SSH RSA key 缩写成 “xx…x” 的形式保存在 cache 中:
var global string
var cache sync.Map
type SSHData struct {
UserId int
RSAKey []byte
}
func AddSSH(data *SSHData) {
// Mask RSAKey to xx...x format
cache.Store(data.UserId, append(data.RSAKey[:2], '.', '.', '.', data.RSAKey[len(data.RSAKey)-1]))
}
func main() {
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
global = string(make([]byte, 1024*1024*100))
for i := 0; ; i++ {
req := new(SSHData)
req.UserId = i
req.RSAKey = randBytes(2048)
AddSSH(req)
time.Sleep(time.Millisecond * 1)
}
}
func randBytes(size int) []byte {
data := make([]byte, size)
for i := 0; i < size; i++ {
data[i] = byte('a' + i%26)
}
return data
}
定位泄漏对象
我们首先访问 http://localhost:6060/debug/pprof/heap 对服务进行一次初次采样,并将结果保存为 heap.old。此时,我们可以看到 heap 的图像显示结果。

由于我们服务自身一启动就会创建 100MB 数据,所以这段 heap profiling 事实上并没有太大参考意义。我们需要查看的,是在一段时间内的两次 heap 采样之间,相对来说增加的那部分内存。
所以我们可以在 1 分钟后,再次访问一样的 URL 进行一次采样,结果保存为 heap.new 。然后执行 go tool pprof -http=:8000 -diff_base=heap.old heap.new ,所得 heap diff 图如下:
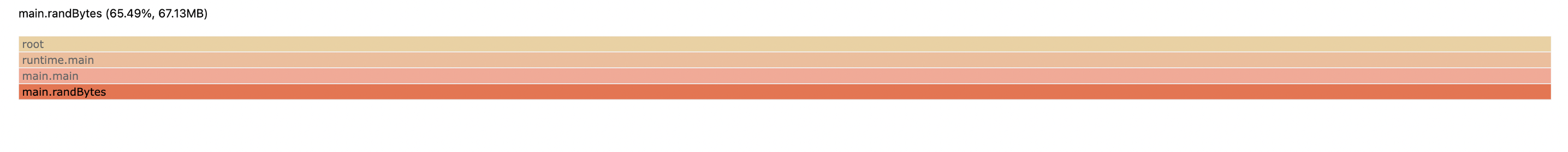
由此我们可以看出,新增内存都是由于 randBytes 这个函数所创建的,而根据代码可知,引用了这个函数返回内容的对象是 RSAKey。
追溯泄漏源头
定位到了泄漏对象,我们就要去追溯代码哪里会持久化引用该对象。由于示例代码很简单,我们可以发现唯一的持久化函数为:
func AddSSH(data *SSHData) {
cache.Store(data.UserId, append(data.RSAKey[:2], '.', '.', '.', data.RSAKey[len(data.RSAKey)-1]))
}
该函数理论上,对于每一个 UserId,会在 Map 里存储 6 字节的对象。而由于 main 函数每秒会调用 AddSSH 1000 次,即每秒泄漏 6KB 的内存。即便如此,我们就算程序运行一小时,也无非泄漏 6 _ 60 _ 60 = 21600KB = 21MB 的数据,不至于一分钟内就泄漏了 60MB。
但如果再进一步去细看 append 函数的细节,我们会发现它最终返回的那个切片对象,底层数组的引用,依然还是原始 randBytes 函数所创建的那个,而切片的部分引用,依然会导致原始对象不能够被完全释放。